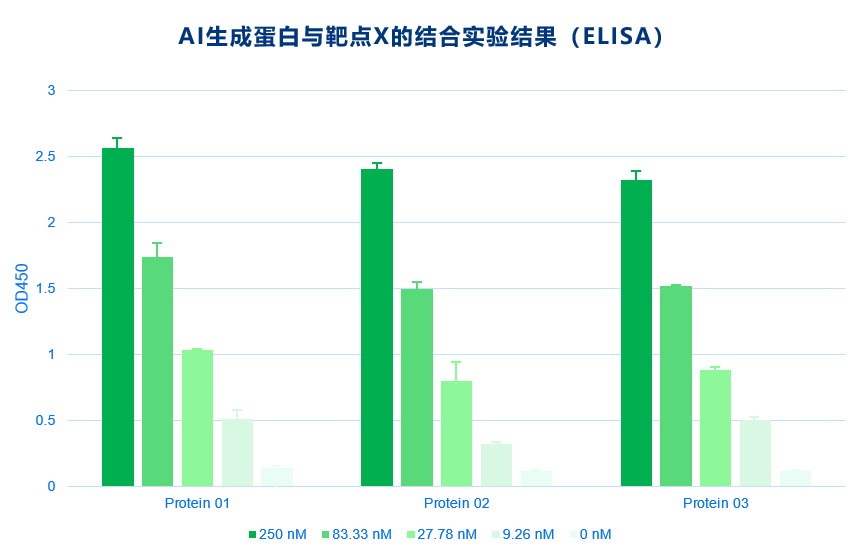
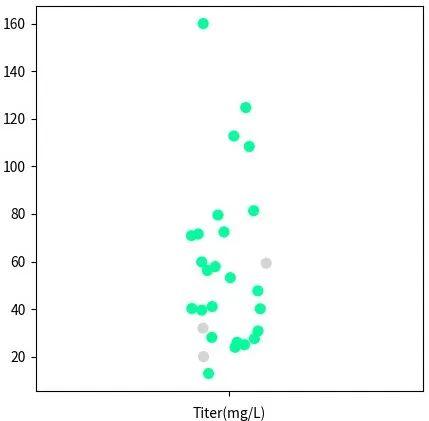
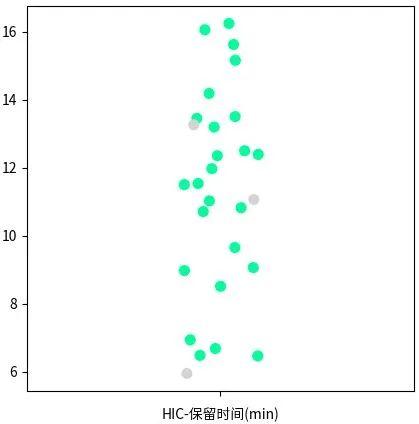
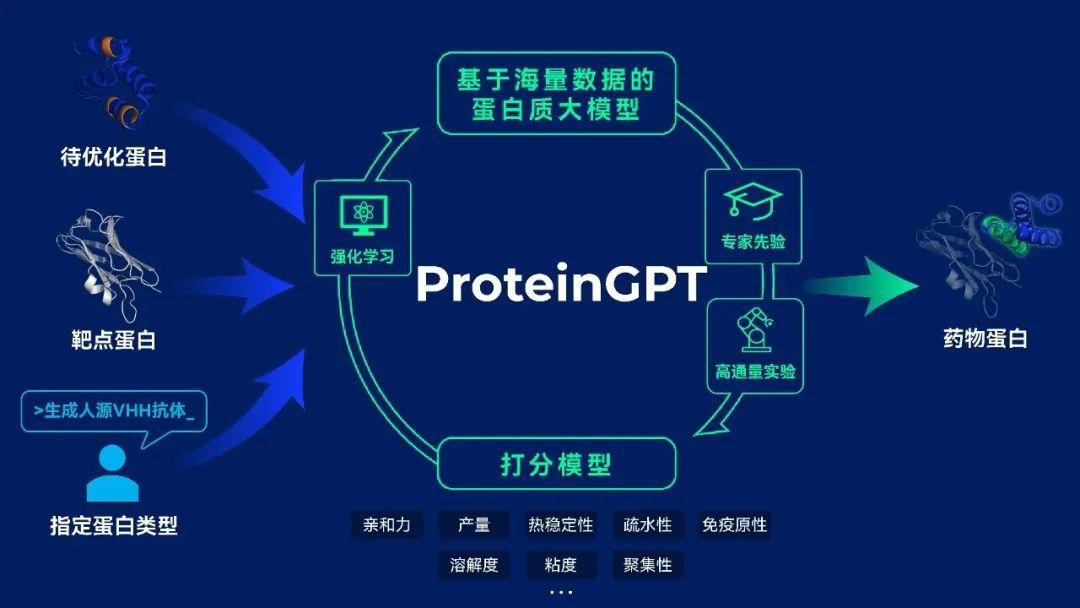
与 ChatGPT 相似,晶泰科技在训练 ProteinGPT 的过程中也使用了无标记的蛋白质序列数据(约 2.8 亿条)+抗体序列数据(包括公开数据集中的数十亿条+晶泰科技内部积累的抗体 NGS 数据),但这些仅仅解决了自监督预训练的部分。高质量的标记数据,特别是与蛋白药物相关的标记数据是非常有限的,如抗体可开发性的公开数据只有 137 条。
为解决数据问题,晶泰科技率先提出“智能计算、湿实验、专家经验三位一体”的创新思路,搭建了国内规模最大的“干湿融合”的大分子药物研发团队,包括近百名科学家和工程师。
其中,湿实验平台既可以通过杂交瘤、展示文库、Single B Cell 等传统方式完成抗体药物从靶点到 PCC 的全流程研发,又可以为 AI 产生大量训练数据;计算团队除了 AIDD 外,还包括生信和 CADD 团队,可以通过 NGS4AI、MD4AI 等方式为 AI 贡献更多的训练数据。
最后,作为国内最早投身 AI 药物研发的企业,晶泰科技已经积累了超过 8 年的经验,在内部形成了 AI 算法向产业转化的一整套最佳实践,在很短时间内为 ProteinGPT 找到了最佳的落地应用场景。
图7. ProteinGPT的模型架构
One more thing...
自去年以来,晶泰科技内部的自动化能力开始走进公众视野,成为放大其 AI 数据优势的利器。除了将自动化运用于化学合成、晶型研究外,晶泰科技也在大分子药物方向部署了高通量的抗体筛选平台(如下图所示)。相较于传统的人工筛选,该平台的筛选通量可提高 1~2 个数量级,能够为内部 AI 模型贡献更大规模、更高质量的训练数据。
目前,晶泰科技在大分子领域的多个 AI 算法均已达到 SOTA 水平(State of the Art,AI 术语,指在公开测试集上取得全球最佳表现),而内部人员将其中相当一部分归功于晶泰科技在内部生成数据上的优势。Automation4AI,正日渐成为打造“生物版 ChatGPT ”的重要引擎。
图8.晶泰科技高通量抗体筛选平台
小结与展望
展望未来,要获得更加通用、好用的 DrugGPT、AntibodyGPT、mRNAGPT 等模型,我们还需要更多领域相关(domain-specific)的数据积累和算法创新。同时,由于相关方向跨学科的性质,我们需要把生物学家、化学家、AI 科学家和软硬件工程师放置在一个屋檐下,通过快速的迭代试错,找到 AI 造福人类生命健康的最佳路径。 参考文献:
[1] Sensor Tower数据
[2] Verkuil R, Kabeli O, Du Y, et al. Language models generalize beyond natural proteins[J]. bioRxiv, 2022: 2022.12. 21.521521.
[3] Madani A, Krause B, Greene E R, et al. Large language models generate functional protein sequences across diverse families[J]. Nature Biotechnology, 2023: 1-8.


 发表于 2023-4-9 19:50:58
发表于 2023-4-9 19:50:58