|
|
(持续更新)
1 Relation-Aware Collaborative Learning for Unified Aspect-Based Sentiment Analysis
2020 ACL-main
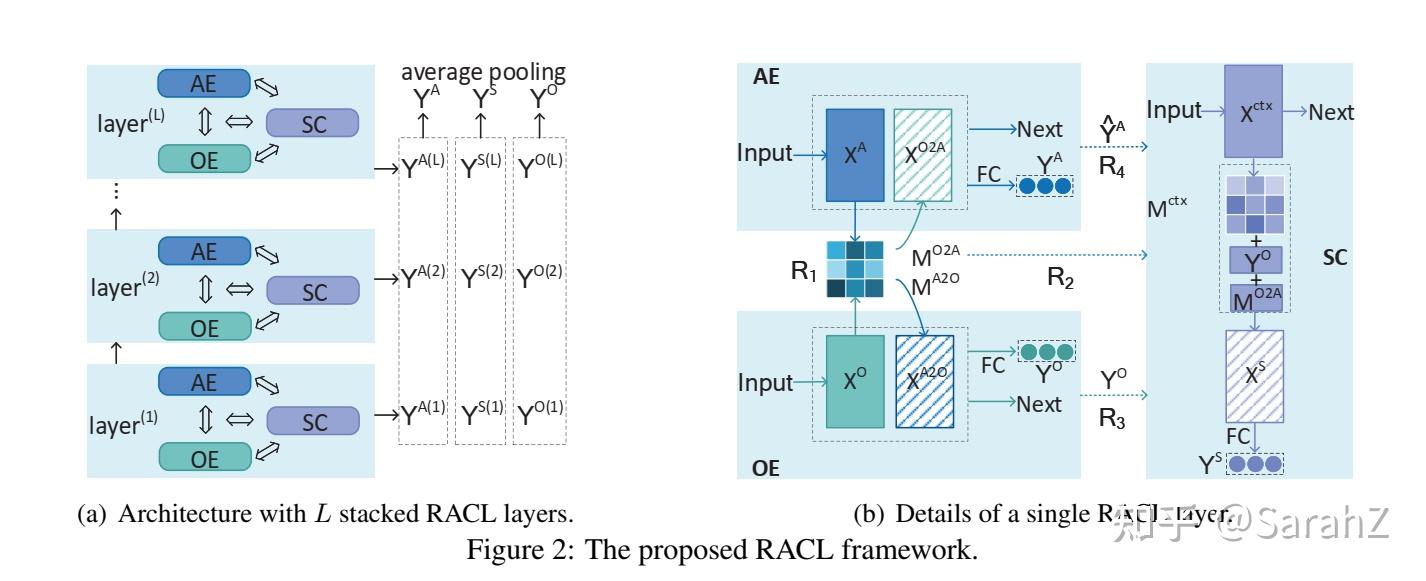
左图是全框架,右图是一个RACL的具体结构
任务定义
给定句子 S_{e}=\left\{ w_{1},w_{2}, ...w_{n}\right\} ,定义三个AE、OE、SC的序列标注问题:
- AE 目的是预测一个tag序列 Y^{A}=\left\{ y_{1}^{A},y_{2}^{A},...,y_{n}^{A} \right\} (和原始句子等长),其中 y_{i}^{A}\in\left\{ B,I,O \right\} 分别表示 begining of, inside of, outside of 一个aspect term。
- OE 目的是预测一个tag序列 Y^{O}=\left\{ y_{1}^{O},y_{2}^{O},...,y_{n}^{O} \right\} (和原始句子等长),其中 y_{i}^{O}\in\left\{ B,I,O \right\} 分别表示 begining of, inside of, outside of 一个opinion term。
- SC 目的是预测一个tag序列 Y^{S}=\left\{ y_{1}^{S},y_{2}^{S},...,y_{n}^{S} \right\} (和原始句子等长),其中 y_{i}^{S}\in\left\{ pos,neu,neg \right\} 分别表示每个单词的极性。
结构解析
1 输入部分是词嵌入经过一个全连接层得到 H
2 首先进行子任务私有特征的编码,得到面向三个子任务的特征X^{A}、X^{O}、X^{S}
利用卷积得到AE-oriented features X^{A} 和OE-oriented features X^{O} ,考虑到的是这两个任务与词的临近词相关性很大。
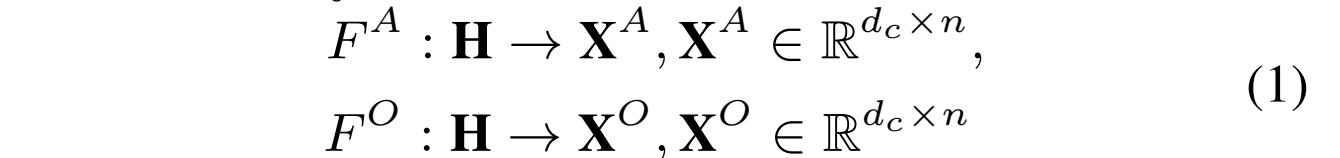
为了得到SC-oriented features
首先从 H 中利用CNN编码上下文特征 X^{ctx} ,然后将共享向量 H 视为query方面,并用注意力机制计算query和上下文特征 X^{ctx} 之间的语义关系,得到 X^{S} (利用的是 X^{ctx} 实现的表达)
3 Propagating Relations for Collaborative Learning

R_{1} 是AE和OE之间的双向关系, X^{O2A} 是OE向AE传递的部分,计算方法是 X^{A} 和 X^{O} 交互,利用X^{O} 表达。然后将交互部分同原来的面向AE的特征 X^{A} 拼接在一起,经过一个线性层和softmax就可以得到任务AE的分类结果。同理得到任务OE的分类结果。
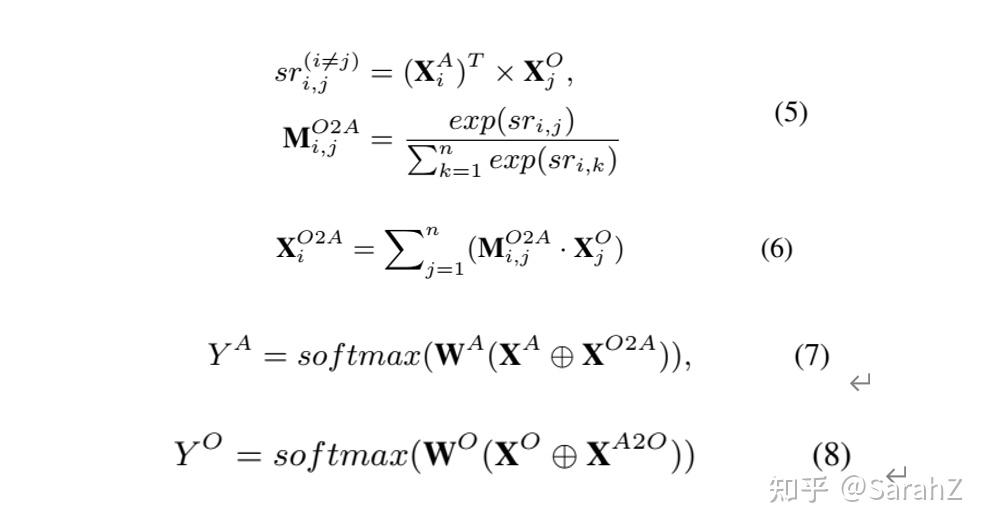
此外,一个单词不可以既是方面词又是情感词,因此加入了合页损失作为正则项来约束 Y^{A} 和 Y^{O}
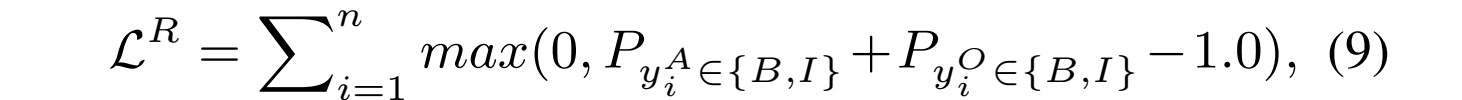
R2 是SC和 R_{1} 之间的三元关系。注意直接使用注意力权重来相加的,而不是在最后阶段。
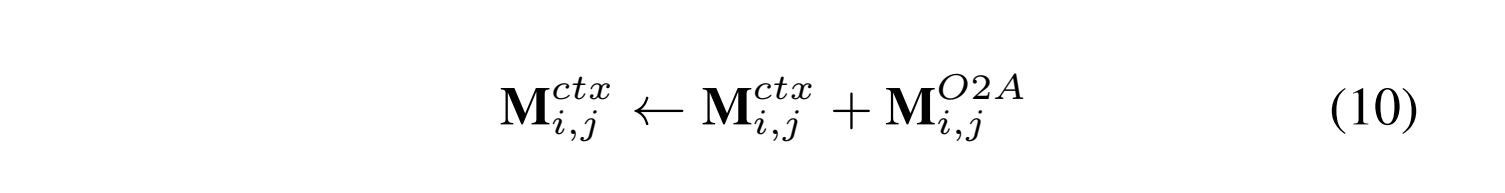
R3是SC和OE之间的双向关系,这表明,在对情感极性进行预测时,需要对抽取出的观点术语多加关注。为了建模R3,采用和R2同样的方式,也就是对SC中的 M^{ctx} 利用生成的 Y^{O} tag序列进行更新,如下:
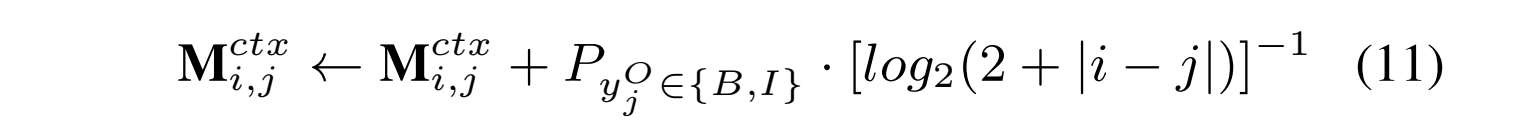
这样的话情感词在注意力机制中可以得到更大的权重,从而有利于情感分类。
得到上述方式完成交互后的 M^{ctx} 后,我们可以按照式子4重新计算面向SC任务的特征 X^{S} ,然后我们将 H 和 X^{S} 拼接在一起作为最后的SC的特征,并将它们经过一个全连接层后去预测方面极性。
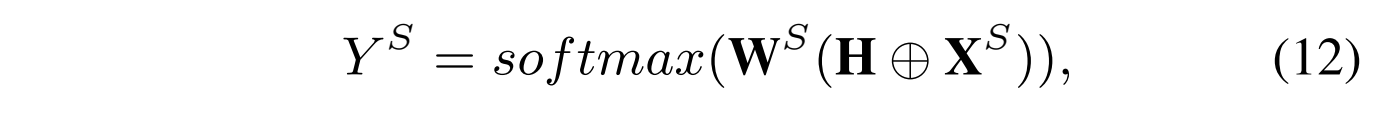
4 Stacking RACL to Multiple Layers
以上是一个RACL模块的输出,本实验堆叠了多个模块。具体来说,我们首先编码第一层特征 X^{ctr(1)} , X ^{A(1)}\oplus X ^{O2A(1)} , X ^{O(1)}\oplus X ^{A2O(1)} ,在第二层将这些特征输入到SC,AE和OE去生成 X^{ctr(2)} , X^{A(2)} , X^{O(2)} 。以此类推可以将RACL堆叠到L层。最后将各层的最终预测结果进行平均池化的操作
这种shortcut-like的架构可以促进低层中的功能具有意义和信息量,反过来这也有助于高层做出更好的预测。
损失函数
最终RACL总的损失的 L 是所有子任务的损失之和加上正则项的损失,也就是 L=\sum_{}L^{T}+\lambda ·L^{R} ,其中 \lambda 是系数, T \in \left\{ A,O,S \right\} .
2 Relational Graph Attention Network for Aspect-based Sentiment Analysis
2020 ACL-main
本文贡献有如下两点:1 提出了一个面向方面的树结构,通过重塑和修剪普通的依赖树来关注目标方面。2 提出了一个新的GAT模型来编码依赖关系,建立方面和意见词之间的联系。
面向方面的树的构建
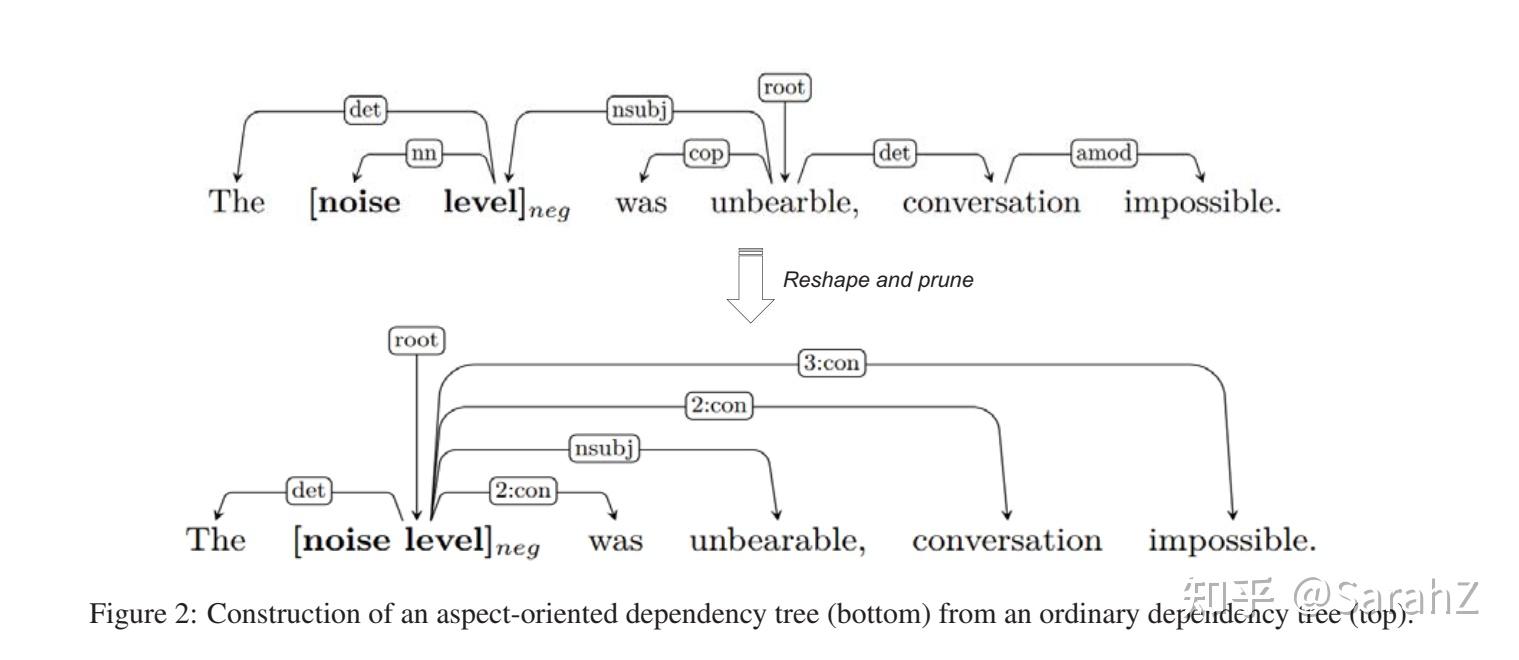
输入:原来的解析结果以及句子和方面。(原文有伪代码)
- 第一步 将目标方面放在根节点
- 第二步 我们将与方面有直接连接的节点设置为子节点,保留原始的依赖关系
- 第三步 舍弃了其他的依赖关系,取而代之的是一个从aspect到每个对应节点的虚拟关系n:con,其中n表示两个节点之间的距离。
注意 如果句子包含多个方面,我们为每个方面构建一个唯一的树。
根据是前人研究证明只关注在语法上接近目标方面的一小部分上下文词就足够了。好处是每个方面都有自己的依赖树,可以减少不相关节点和关系的影响,同时这种统一的树结构不仅使模型专注于方面和情感词之间的联系,而且在训练过程中便于批量操作和并行操作。
R-GAT
为了对上述树进行编码,在GAT的基础上提出了一个新的R-GAT:relation graph attention network
GAT实现的是:
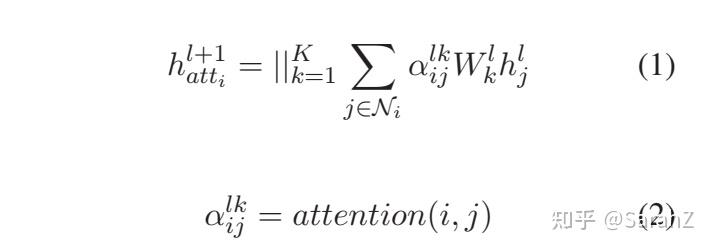
每个结点只对邻居结点进行注意力计算权重。这个得到的是 h_{att} 。注意 ||_{k=1}^{K} 表明一共使用了K个 W_k 做转换矩阵,最后将它们得到的结果拼接到一起。
作者认为没有考虑到和相邻接点的依存关系是存在不同的,不可以用同样方法去计算。因此引入了考虑不同的依存关系的R-GAT来补充信息。大致的思想相同,只是对于(1)中的 \alpha_{ij} 有考虑进新的信息,也就是不同的依存关系
R-GAT
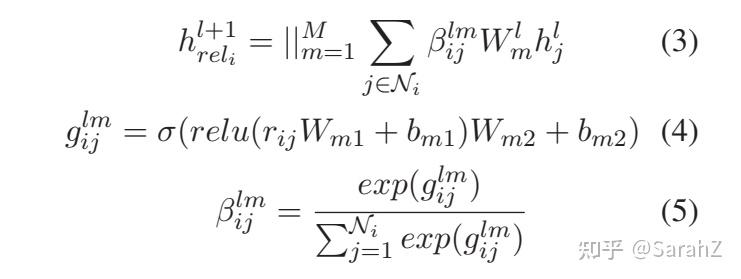
作者将各种依存关系映射到嵌入中,结点i和结点j之间的就是rij
也就是先将依存关系经过两层线性层,然后对一个结点的所有边的结果归一化,变成对应的 \beta 系数。
整个网络结构
结构很简单如下:
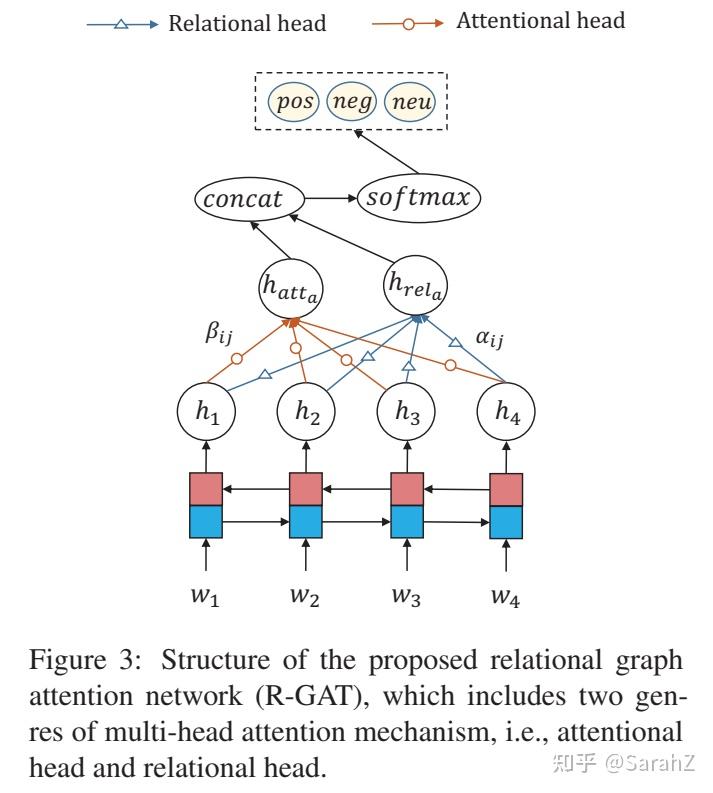
具体来说首先需要把句子的依存分析结果通过变换得到面向方面的数,这个结果将参与后续的图编码。
- 第一步,将句子的词嵌入经过BiLSTM编码得到 h_i ,利用另一个BiLSTM编码方面词作为根节点嵌入的初始化。
- 第二步,利用GAT和R-GAT分别去处理h,得到 h_{att} 和 h_{rel} ,注意相当于只用处理一个根节点。将得到的结果拼接到一起,再经过一个线性层就是该方面词的表达。
- 第三步,softmax分类得到方面词预测结果。
Loss Function
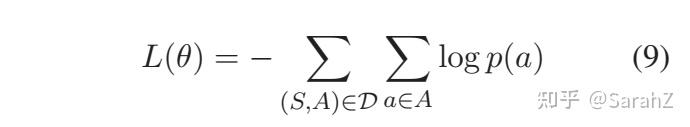
3 Discrete Opinion Tree Induction for Aspect-based Sentiment Analysis
文章贡献:在本文中,我们探索了一种简单的方法,为每个方面自动生成离散意见树结构。用到了RL。
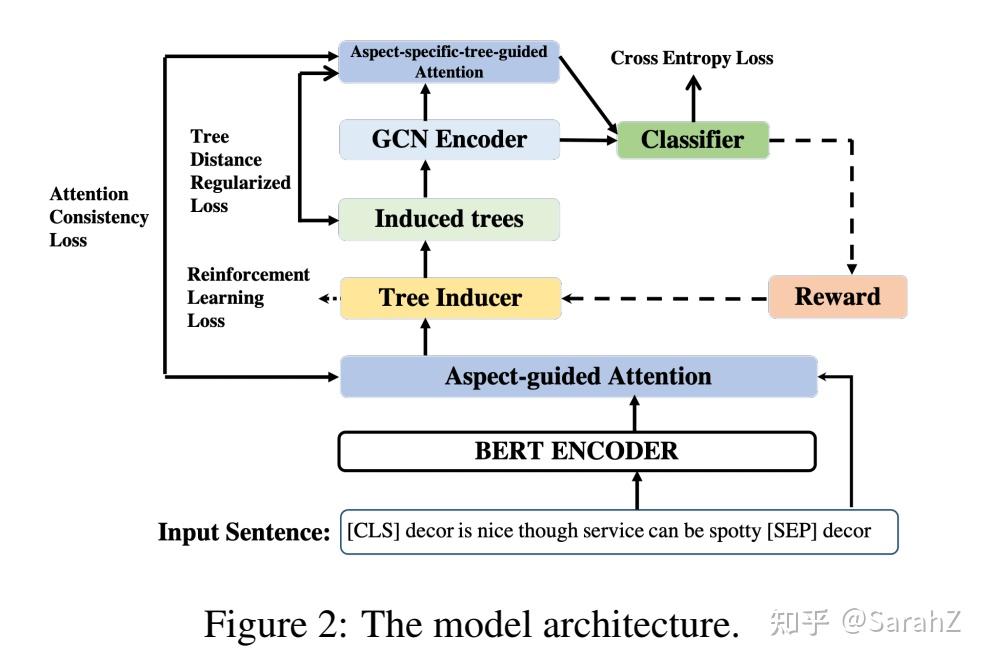
首先为每个方面生成离散意见树,设方面词的位置为[b,e],则首先将方面跨度[b, e]作为根节点,然后分别从跨度[1,b−1]和[e+1, n]构建它的左子节点和右子节点。为了构建左子树或右子树,我们首先选择span中得分最大的元素作为子树的根节点,然后递归地对相应的span分区使用build_tree调用。(除了方面词外其他node都是单个词)。
关于得分分数的计算,选择将" [CLS], w_1,w_2,...,w_n,[SEP],w_b,...,w_e "作为BERT的输入得到特殊于方面词的句子表达H,然后按照如下计算得分:
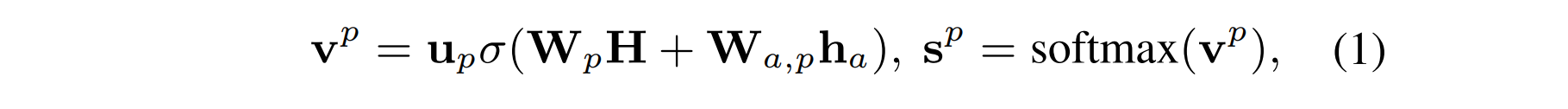
其中h是H中方面词部分的平均池化,构建树的这部分包含的参数有三个 u_p,W_p,W_a 以及BERT参数部分。
构建树的这一部分称为 Q_\phi(t|x,a) ,输入为x和a(用于打分),输出为一棵树,参数 \phi 包括上述参数。这一部分参数使用RL进行更新而不是最终损失函数的反向传播。
生成树以后开始正式执行预测任务,模型非常简单。
将上面得到的树生成邻接矩阵,经过GCN(可能多层),取最后一层GCN的输出结果的方面词部分以及[CLS]这个token的表达之和作为query,与GCN的输入的初始向量特征(也就是原句子经过句子编码器得到的)做注意力机制,用输入去表达最终的方面级分类特征。
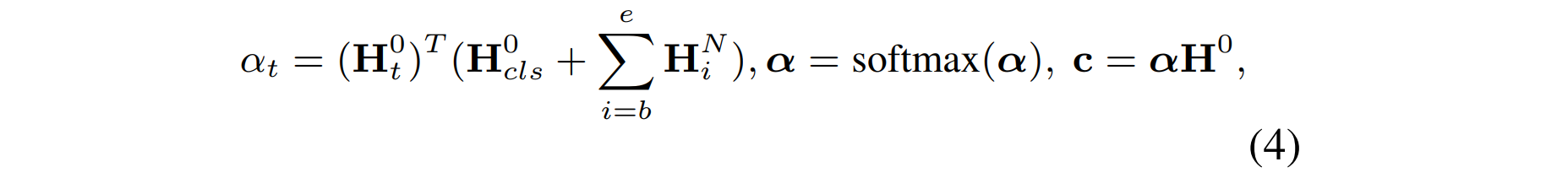
最后输出分类结果
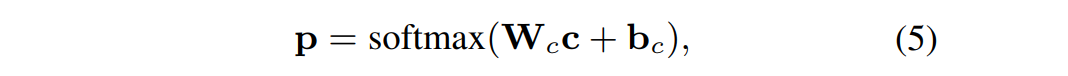
损失函数:
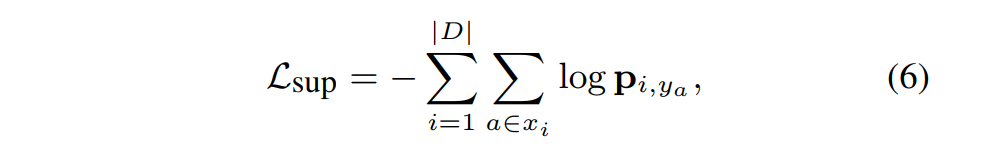
注意这个论文分为两个模块,第一个是生成树,利用 Q_\phi(t|x,a) 得到t;第二部分是预测, P_\theta(y|x,a,t) ,这里的 \theta 包括GCN模块的参数和输出(等式5)的部分,PS注意力模块没有引进参数哦。
第二部分使用上述损失函数进行优化,由于树的采样过程是一个离散的决策过程,因此它是不可微的,第一部分使用的是RL进行优化。
强化学习实现训练部分还没看。
4 Improving Aspect-based Sentiment Analysis with Gated Graph Convolutional Networks and Syntax-based Regulation
任务描述:
输入是句子X(长度为n, [x_1,x_2,...,x_n] ),同时有方面词的索引t,得到方面词 x_t 。输出是对方面词的情感分析。
(i) Representation Learning
将 \tilde{X}=[CLS]+X+[SEP]+x_i+[SEP] 输入到预训练好的BERT中,得到最后一层隐含层表达。(需要注意的是这一层并不是原来的一个个词哦,因为BERT里面有个小模块是WordPiece,它把单个词分成更小的字词。)然后对每个原始词 x_i 的隐含层字词向量做平均得到每个词的词嵌入表达 e_i 。最后,我们还使用BERT中的特殊标记[CLS]的隐藏向量s对整个输入句子X及其方面术语 x_t 进行编码。
(ii) Graph Convolution and Regulation
这一部分的核心思想就是给GCN的每一个隐含层的各个词向量都经过一个基于方面词的门控向量进行信息的过滤。操作方法如下:输入层的词嵌入是 e_1,...e_n ,经过GCN的第 l 层隐含层表达为 h_i^l 。每层的门控向量计算如下 g_l =\sigma(W_j^g e_t) ,经过门控约束后的隐含层的表达结果为 \bar{h_i^l}=g_l\circ h_i^l ,使用的是元素乘。
理想情况下,我们期望GCN不同层的隐藏向量将捕获句子中不同层次的上下文信息。因此,这些层的门向量gt也应该显示出一些上下文信息的差异水平,以匹配GCN隐藏向量中的那些信息。
实现门控的差异化的方法是添加一个惩罚函数。在完成GCN(以及对应的门控)后,以第 l 层为例,首先计算盖层所有隐含层向量的最大池化 \bar{h^l} ,然后用 l 层以外层( l'层 )的门控向量去乘以该层的隐含层向量(元素乘)\bar{h_i^{l,l'}}=g^{l'}\circ h_i^l,同样得到 \bar{h_i^{l,l'}} 的最大池化 \bar{h^{l,l'}} ,对于所有的 l'\ne l 的 \bar{h^{l,l'}} 和 \bar{h^l} 之间最小化余弦相似度可达到差异化门控的效果。对应的惩罚函数如下:
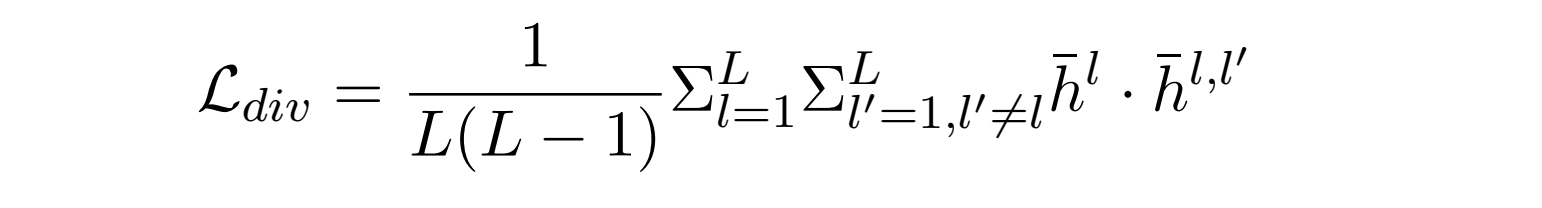
(iii) Syntax and Model Consistency
作者希望进一步利用语法信息去是模型达到更好的效果,从ABSA方面词临近词的上下文重要性出发,为每一个词计算了在语法信息结构上对任务的重要性分数:利用依存分析树上 x_i 到 x_t 距离负数(结果再经过softmax归一)表示重要性分数 syn_i .
为了使上述的句法结构的重要性分数可以指导模型从而取得更好的效果,采用的思想是使基于模型的每个单词的重要性分数分布能和 syn 的分布尽可能相近。记基于模型每个单词的分数为 mod_i ,思想是如果该单词的表达与最后用于分类的特征的距离越相近分数越高(与分类越相关),计算方式如下:
最后的特征表征为 V = [s; max pool(h^L _1 , ...,h^L_n)] ,单词与其相似度 mod_i = σ(W_V V ) · σ(W_Hh^L_ i ).
惩罚函数:最小化 syn 和 mod 的KL散度:
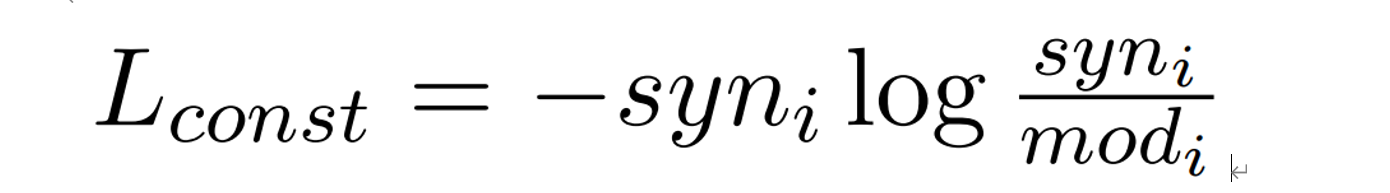
利用 V 直接就可以做情感分类。
损失函数:
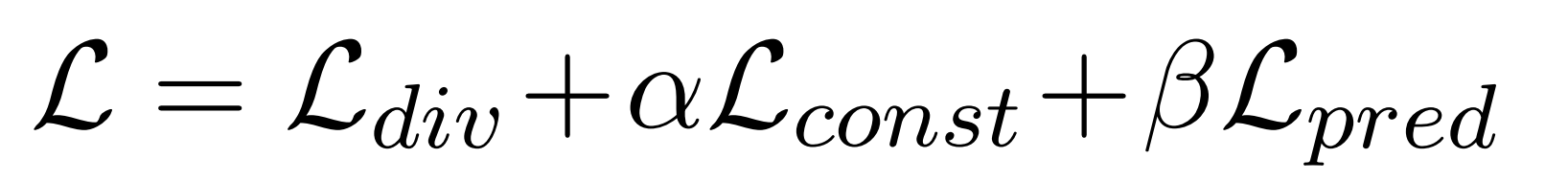
第一项是分类结果的,后面两惩罚函数
5 Dynamic and Multi-Channel Graph Convolutional Networks for Aspect-Based Sentiment Analysis
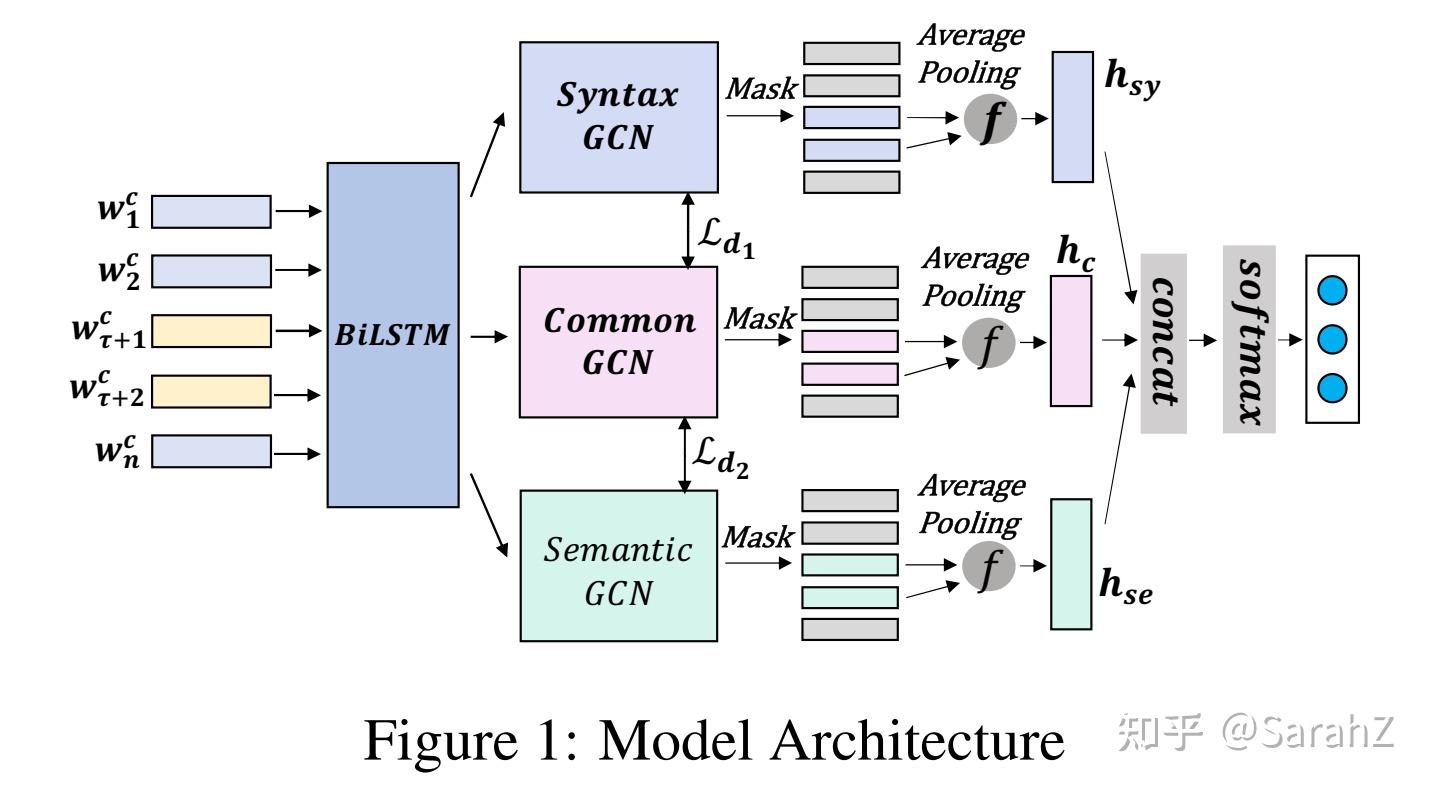
第一步:Embedding and Bidirectional LSTM
原句子一共n个words,其中方面词从位置t开始长m个word,首先在嵌入矩阵中找到句子对应的低维向量,然后把句子丢到双向LSTM中去学习给定句子的隐含层表征 H^c (由双向的结果cat) \in R^{n \times d_{lstm}}
第二步:Syntactic Graph and Convolution Module
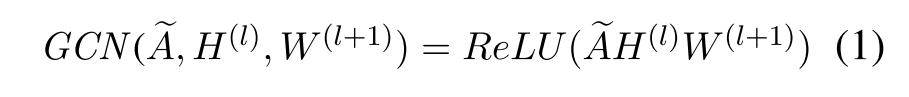
这是图卷积的一层的表达式
第一层的输入特征向量为LSTM编码完的向量,维度为 d_{lstm} 。其他每一层的输入是前面每一层输出的concat,因此设每一层GCN的输出结果维度为 d_{gcn} 的话,第(l+1)层的输入维度为 d_{lstm}+l \times d_{gcn} 。临界矩阵是self-loop的(没搞懂左右两个-1/2干啥的还)
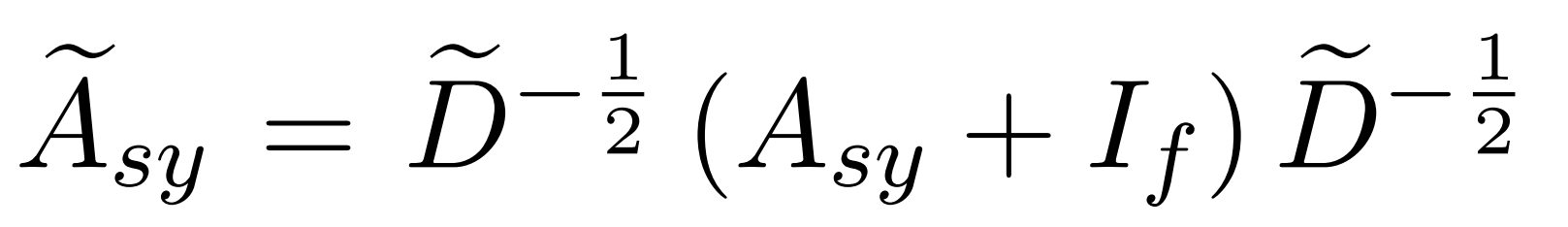
最终得到第L层输出 H_{sy}^L 成功完成对语法信息的表征。
Semantic Graph Convolution Module
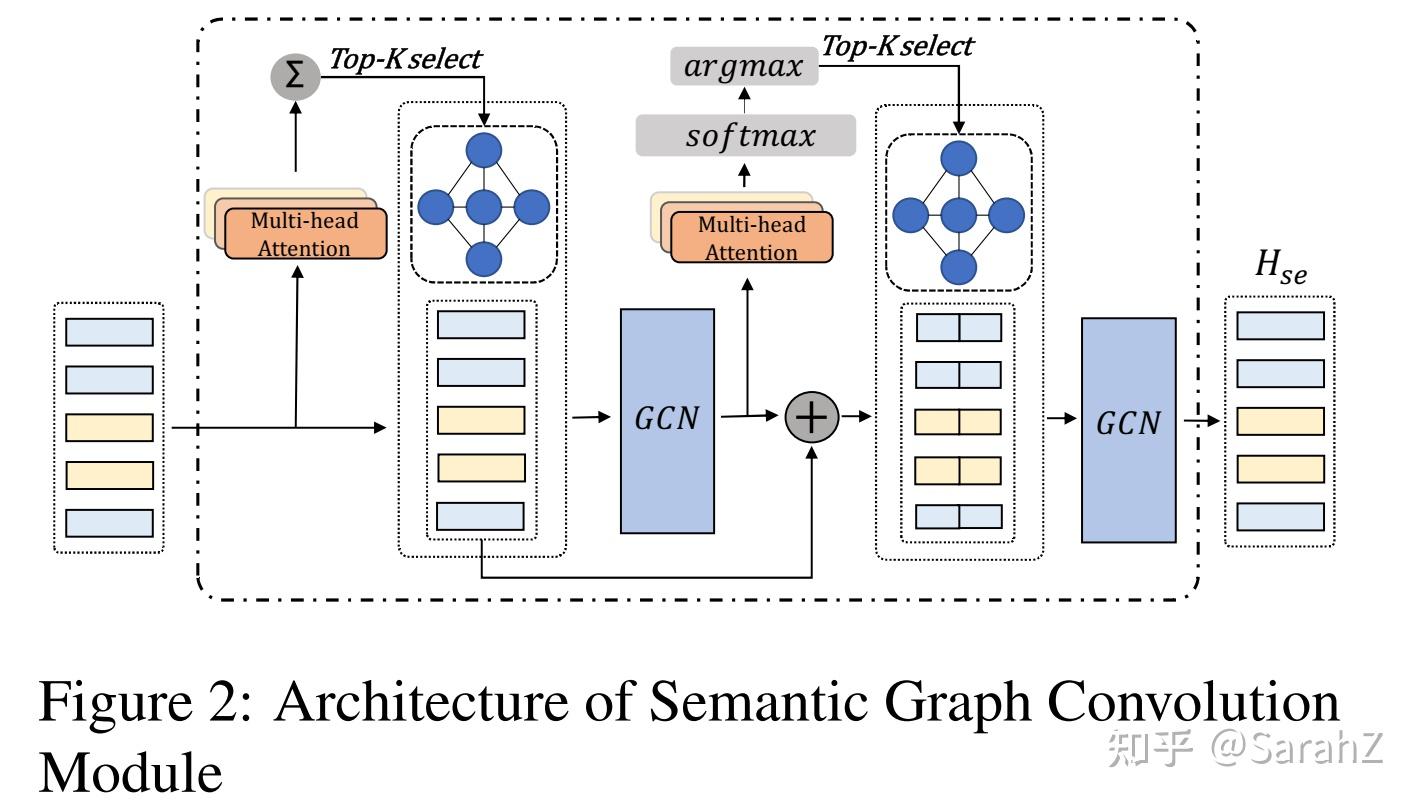
第一层:将输入(也就是LSTM编码的)经过多头注意力得到K个注意力矩阵,对这K个注意力矩阵之和使用top-k selection(只留下最重要的k个上下文)(当然也要保证这个邻接矩阵,也就是top-k处理后的矩阵的对称性),以此为邻接矩阵, H^c 为特征矩阵进行卷积。

往后其他层的输入就是前面所有层输出的concat,同样经过多头注意力计算K个矩阵,然后利用softmax函数得到每个注意力矩阵的概率,选择最大概率的那个进行top-k函数后作为邻接矩阵参与下一层的GCN。

如此得到最后一层的输出为语义表达。结果为 H_{se}^L
第三步:Common Convolution Module
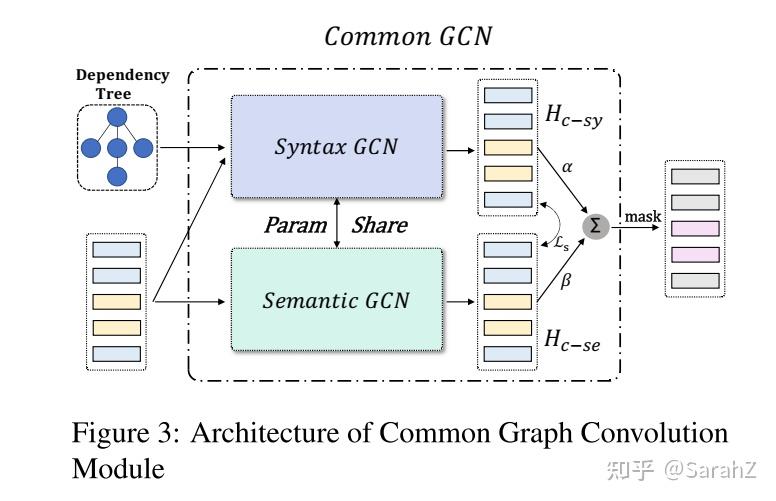
作者认为语义空间特征和语法空间特征是部分重合的,这部分信息也可以帮助句子完成任务。这一部分就是提取这些特征的。记上面的两个模块表达式如下:
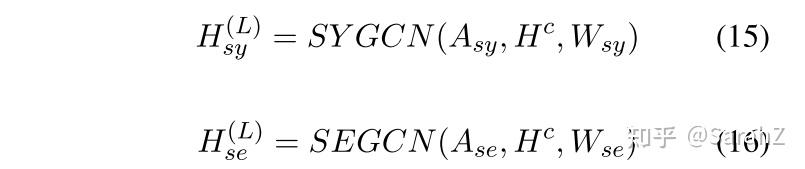
这个模块首先得到语法共同表达,注意参数共享
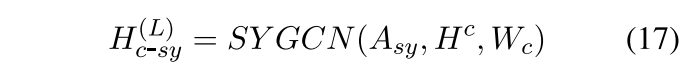
和上面基本一样,但是需要注意的是这里的变换矩阵Wc是共享参数的
同理语义共同表达,注意参数共享,应该是和语法那个Wc共享的
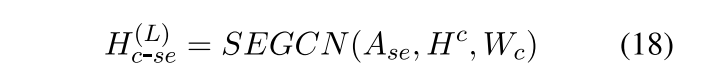
最后表达,加权除以二,注意两个系数是可训练的。
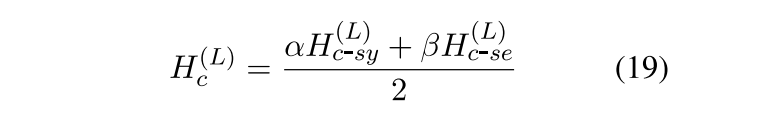
Feature Fusion
首先用mask只留下aspect的表达向量,然后concat
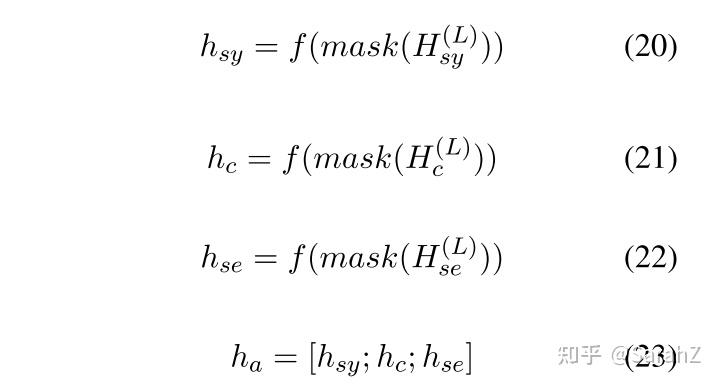
f是平均池化
作者认为最终分类需要考虑到来自三个模块可能占不同的权重,因而需要经过一个MLP层。
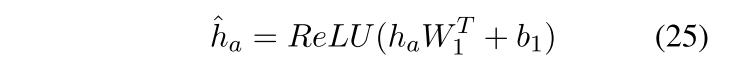
该模型能够自适应地融合句法、语义及其组合表示,为情感分类提供更深层的关联信息。
Model training
最终分类结果
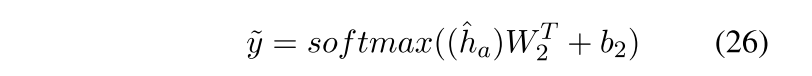
有两个针对于模型引进的惩罚函数,一个是为了使得syn和c-syn学的的东西尽量不同(因为邻接矩阵和input都一样),采用的想法是使它们的正交性增强。同理sem和c-sem
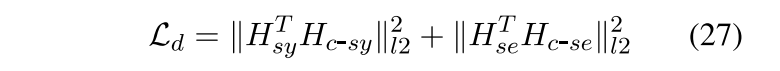
另一个是确保Common Convolution Module部分syn和sem学到的一致性的东西尽可能相近。
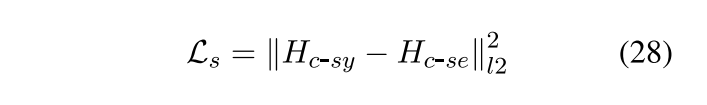
最后总的损失函数
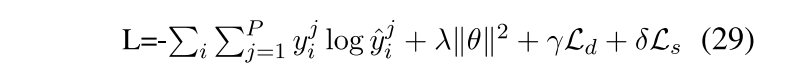 |
|


 发表于 2022-9-28 21:18:35
发表于 2022-9-28 21:18:35