|
|
上篇文章主要为了描述法律应用场景当下精调模型下工程实现的方法。目前精调模式下技术方面会用到“预训练模型”,先进行预训练阶段,然后是Fine-tuning(微调),也会将法律专家的专业知识融入到模型中实现应用场景。本文主要是为了描述chatGPT的相关技术优势,思考chatGPT对法律人工智能的影响。
目前chatGPT在基本的法律文书生成、合同审查、法律检索、实体要素抽取、法律咨询等方面还是有一定的表现,不过在量刑预测、法律语言的严谨度、专用法律要素提取等方面跟目前垂直领域厂商的模型还是有一定差距的。
原因之一是目前chatGPT对法律数据的缺乏,由于学习的不够全面,导致目前使用效果不是很好,从ChatGPT技术发展来超过目前领域模型还是值得期待的,当然会有一个过渡阶段。
NLP的范式发展经历的两个阶段。
第一个阶段从深度学习到两阶段预训练模型
主要是2013年引入NLP到2020年5月GPT3.0,这个阶段从改进LSTM(长短记忆 CNN方向)模型及少量改进的CNN模型为特征抽取器;以Sequence(序列) +Sequence (叫Encoder-Decoder亦可)+Attention(序列-序列-注意力)作为各种具体任务典型的技术架构。两阶预训练模型主要是BERT和GPT模型。这个阶段后期大多数NLP子领域的研发模式切换到了两阶段模式:模型预训练阶段+应用微调(Fine-tuning)或应用Zero/Few Shot Prompt模式。
第二阶段从预训练模型走向通用人工智能
这个从20年6月GPT3.0出现之后到现在,经历了“自回归语言模型+Prompting”模式到“自回归语言模型+Instruct”模式,实现人工智能从命令式到更符合人的交流方式。
GPT3.0后有什么优势
市场是靠脚投票,目前规模最大的LLM模型,几乎清一色都是类似GPT 3.0这种“自回归语言模型+Prompting”模式的,比如GPT 3、PaLM、GLaM、Gopher、Chinchilla、MT-NLG、LaMDA等,没有例外。
chatGPT作为“自回归语言模型+Instruct”模式,首先在形式上统一了自然语言理解和自然语言生成任务的外在表现形式。第二个,如果想要以零示例提示语(zero shot prompting)或少数示例提示语(few shot prompting)的方式做好任务,则必须要采取GPT模式。
为什么必须用GPT呢,这个需要分析什么是理想的LLM(大语言模型)模型,下图是理想的LLM模式。
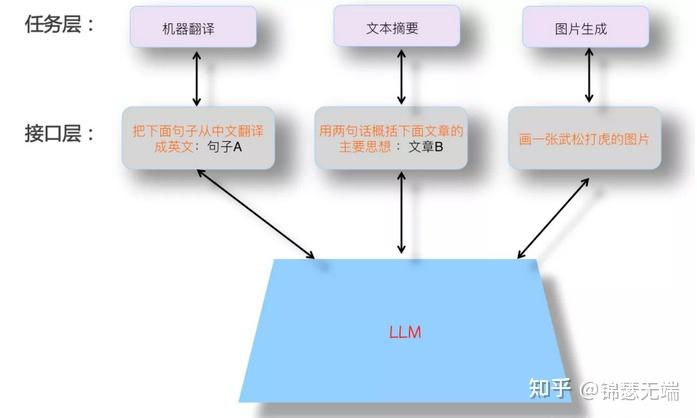
那理想的大语言模型具备哪些特点呢。首先,LLM应该具备强大的自主学习能力。其次,LLM应该能解决NLP任何子领域的问题,而不仅支持有限领域。再者,当我们使用LLM解决某个具体领域问题的时候,应该用我们人类习惯的表达方式,就是说LLM应该理解人类的命令。
GPT是符合理想大语言模型特点
第一,这个LLM模型规模必然非常巨大,参数很大,具备很强的自学习能力,同时模型规模大各领域任务支持能力就强。
第二,zero shot prompting也好,few shot prompting也好,甚至促进LLM推理能力的思维链(CoT,Chain of Thought)Prompting也好,能够实现理解人类的命令。
chatGPT在法律的应用前景
既然ChatGPT是可以直接去追求理想LLM模型的,那么,未来的技术发展趋势应该是:追求规模越来越大的LLM模型,通过增加法律行业预训练数据的多样性,来涵盖越来越多的业务,LLM自主从法律数据中通过预训练过程学习法律知识,随着模型规模不断增大,很多上面的问题随之得到解决。研究重心会投入到如何构建这个理想LLM模型,而非去解决法律的具体问题。前期存在GPT与法律领域模型想结合的情况,不过随着技术的不断发展,大模型慢慢就不再需要领域模型。
本内容暂时不讨论可能存在的问题。 |
|


 发表于 2023-4-19 15:59:37
发表于 2023-4-19 15:59:37

