|
|
这次要介绍的文章是2004年发表在KDD的《Mining and Summarizing Customer Reviews》,是一篇经典的情感分析的论文。文章主要工作是收集商品的评论信息,通过处理得到对商品各个属性维度的正面或者负面评价。文章没有过多地涉及nlp相关的算法,亮点更多的是整个处理的流程思路,以及细节方面的处理。下面是具体介绍。
一.流程介绍
1.1 主要步骤
整个流程图如图1,主要步骤如下:
- 通过爬取商品的评论信息来获取数据
- 基于句子的文本预处理与商品属性提取
- 评论词汇提取与情感方向划分
- 汇总整理商品的属性及情感方向

图1 商品评论概要系统整体架构
本文主要对论文中的2-4步骤做详细的介绍。
1.2 基于句子的文本预处理与商品属性提取
对文本的预处理采用的方法是常见的几种,包括去除stopping words(停顿词),stemming(词干或者词根提取),fuzzy matching(模糊匹配)。随后对单词进行词性的标注。在论文中,处理的最小粒度为句子而非整个评论,因为在商品评论中往往存在某几句话会表达对部分商品属性的正面评价,而其他句子表达的是对其他商品属性的负面评价。
- stopping words: 在英语中,类似 is,a,the,and 这样的词汇在语句中会经常出现,但是它们对句意的表达没有太多作用,因此在处理时会做删除处理
- stemming: 将单词还原为词根形式,即不可再拆分的形式。如unhappiness的词干为happy
- fuzzy matching: 由于评论是用户输入,所以难免有拼错等情况出现,所以做了模糊匹配
对于常见的商品属性的提取在上一步处理完成后进行。所谓常见的商品属性,指的是通过明确的名词或者名词短语来表达商品属性的词汇,如对于手机来说:重量,尺寸,摄像头像素等都属于比较容易提取的属性词汇。列举出常见的商品属性后,在提取时按照模糊匹配的方式进行提提取。
对于提取的商品属性还需要做剪枝处理:
- 对于包含两个及以上词汇的商品属性,去除有可能无意义的商品属性。在做商品属性提取时没有考虑到单词之间的距离关系。当两个描述商品属性的词按照特定顺序出现在一起时表达的属性短语往往更有意义,这时候需要对没有按照特定顺序出现的商品属性短语做剪枝处理。
- 对于多个商品属性都包含某个词汇,去除冗余的部分。这里使用p-support来表达,p-support的含义为:对于一个商品属性词ftr,p-support表示出现ftr并且不出现包含ftr短语的句子数量。当一个属性词的p-support值小于指定值将会被剪枝。对于'life'来说,它的p-support值低于'battery life',有很大概率被剪枝。
但这样做会有漏掉部分商品属性的可能。在评语中,有的时候一句话虽然表达了某个属性的评论,但在文字中不能直接进行提取,同样用手机举例,当有评论“照片很清晰,360度照亮我的妹”可以很清楚知道是对摄像头像素这个属性的评论。
对这种不能直接提取的商品属性,采取的方法如下。
/* 提取非常见的商品属性 */
for each sentence in the review database
/* 当不存在常见属性且存在一个及以上评论词汇时 */
if (it contains no frequent feature but one or more opinion words)
/* 搜索评论词汇最近的名词或者名词词组,将其视为非常见的商品属性*/
{ find the nearest noun/noun phrase around the opinion
word. The noun/noun phrase is stored in the feature
set as an infrequent feature. }一个可能存在的问题是无法找到名词或者名词词组,原因是因为人们在形容多个商品属性时会使用同样的单词,这样的情况在整体的占比为15-20%,而且相对于常见的属性重要性也较低,因此对结果的影响相对较小,因此可以忽略。
1.3 评论词汇提取与情感方向划分
为了做情感方向的划分,判断用户对某一个商品属性的好评与差评,需要提取主观的评论词。一些相关工作在区分表达主观意见和客观描述上面证实,形容词的出现与主观表达的相关性很高。因此使用形容词作为评论词汇。对于包含一个或多个商品属性的一句话,我们称之为opinion sentence,提取方法如下:
for each sentence in database
if (it contains a frequent feature, extract all the adjective
words as opinion words)
for each feature in the sentence
the nearby adjective is recorded as its effective opinion.
/* 相邻的adj表示修饰常见商品属性的名词或者名词短语最近的一个形容词 */情感划分最主要的工作是标记每个评论词汇的情感方向,即正负方向。解决办法便是用已知的工具来对单词的情感进行方向标记。WordNet[1]是由Princeton 大学的心理学家,语言学家和计算机工程师联合设计的一种基于认知语言学的英语词典,可以用来表示同义词和反义词关系,如图2。

图2 WordNet的同义词,反义词结构
WordNet的缺点是不能涵盖所有的词汇。而一些研究通过大规模的语料库和标记好的训练数据来做情感标记,取得了较好的效果。为了使用已有的数据而非构建语料库,更轻松地完成工作,文章作者提出了初始化足够数量已知情感方向的词汇作为seed_list,再利用词汇在WordNet中的同义词和反义词的方式去扩充seed_list的方法。伪代码如下:
Procedure OrientationPrediction(adjective_list, seed_list)
begin
do {
size1 = # of words in seed_list;
OrientationSearch(adjective_list, seed_list);
size2 = # of words in seed_list;
} while (size1 ≠ size2);
end
Procedure OrientationSearch(adjective_list, seed_list)
begin
for each adjective wi in adjective_list
begin
if (wi has synonym s in seed_list)
{ wi’s orientation= s’s orientation;
add wi with orientation to seed_list; }
else if (wi has antonym a in seed_list)
{ wi’s orientation = opposite orientation of a’s orientation;
add wi with orientation to seed_list; }
end for;
end对于还是无法识别的词汇,作者认为意义不大,可以省去,也可以自行添加到seed_list中。
1.4 汇总整理商品的属性及情感方向
每句话中含有多个评论词时,需要综合所有词汇的方向来判断最终的情感方向。当正反方向的词汇数量相等时,使用所有有效评论的平均方向或者之前评论意见的方向。具体如下方伪代码:
Procedure SentenceOrietation()
begin
for each opinion sentence si
begin
orientation = 0;
for each opinion word op in si
orientation += wordOrientation(op, si);
/*Positive = 1, Negative = -1, Neutral = 0*/
if (orientation > 0) si’s orientation = Positive;
else if (orientation < 0) si’s orientation = Negative;
/* 当正反方向评论词相等时*/
else {
for each feature f in si
orientation += wordOrientation(f’s effective opinion, si);
if (orientation > 0)
si’s orientation = Positive;
else if (orientation < 0)
si’s orientation = Negative;
else si’s orientation = s{i-1}’s orientation;
} end for;
end
Procedure wordOrientation(word, sentence)
begin
orientation = orientation of word in seed_list;
If (there is NEGATION_WORD appears closely around word in sentence)
orientation = Opposite(orientation);
end最后的整理形成图3的结果:

图3 商品的评论提取展示
二.实验结果以及结论
作者对5类商品进行特征,评论词以及情感方向的标注。并且在三个方面来对系统的表现做了验证,并且对比了FASTR,一个实体提取和索引系统。对比如下:
1. 属性提取的有效性
2. 评论词语提取的有效性
3. 情感方向预测的准确性
图4在各个步骤的Recall和Precision整体上是不断提高的,对比图5所示的FASTR系统,文章提出的系统表现要好很多。

图4 系统在各个步骤的表现

图5 FASTR在同样的数据集上的表现
图6中展示了评论词提取和句子情感方向准确性的表现。在情感方向上,有着平均84.2%的准确率,还是较高的。
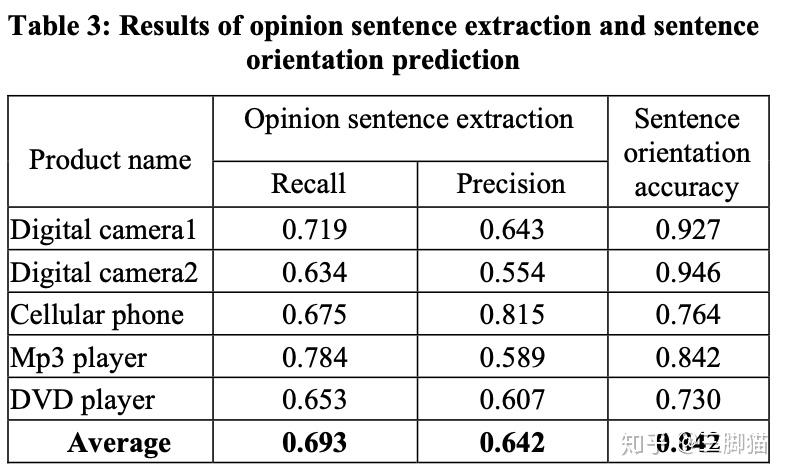
图6 评论词提取和句子情感方向准确性的表现
论文中的很多文本提取方法相对粗糙,如对非常见特征的提取,以及判断情感方向时只是通过情感词方向的正负累加。而情感分析可以采用文本分类算法或者神经网络完成。但整体处理方法依然有参考意义。
参考
- ^https://baike.baidu.com/item/Wordnet/10349844?fr=aladdin
|
|


 发表于 2022-11-28 16:06:41
发表于 2022-11-28 16:06:41